Lab 4: Transforms
Please put your answers to written questions in this lab, if any, in a Markdown file named README.md in your lab repo.
Introduction
Welcome to lab 4! The purpose of this lab is to help you get more comfortable with 2D & 3D transformations and coordinate spaces.
By the end of this lab, you should be able to construct transformation matrices and apply them to manipulate objects in a scene. This familiarity with transformations will also help you when moving between the different coordinate spaces used in building your raytracer.
Objectives
This lab involves less coding and more conceptual understanding than previous ones. Be sure to take your time reading through the sections, and don't be afraid to ask questions if you're confused!
- Learn how matrices are used to represent scaling, rotation, and translation transformations,
- Understand how to compose multiple transformations to obtain a cumulative transformation matrix,
- Define a camera's position and rotation using a view matrix, and
- Use model and view matrices to move between object, world, and camera spaces.
Constructing Transformations
Representing Transformations as Matrices
A transformation can be thought of as a function:
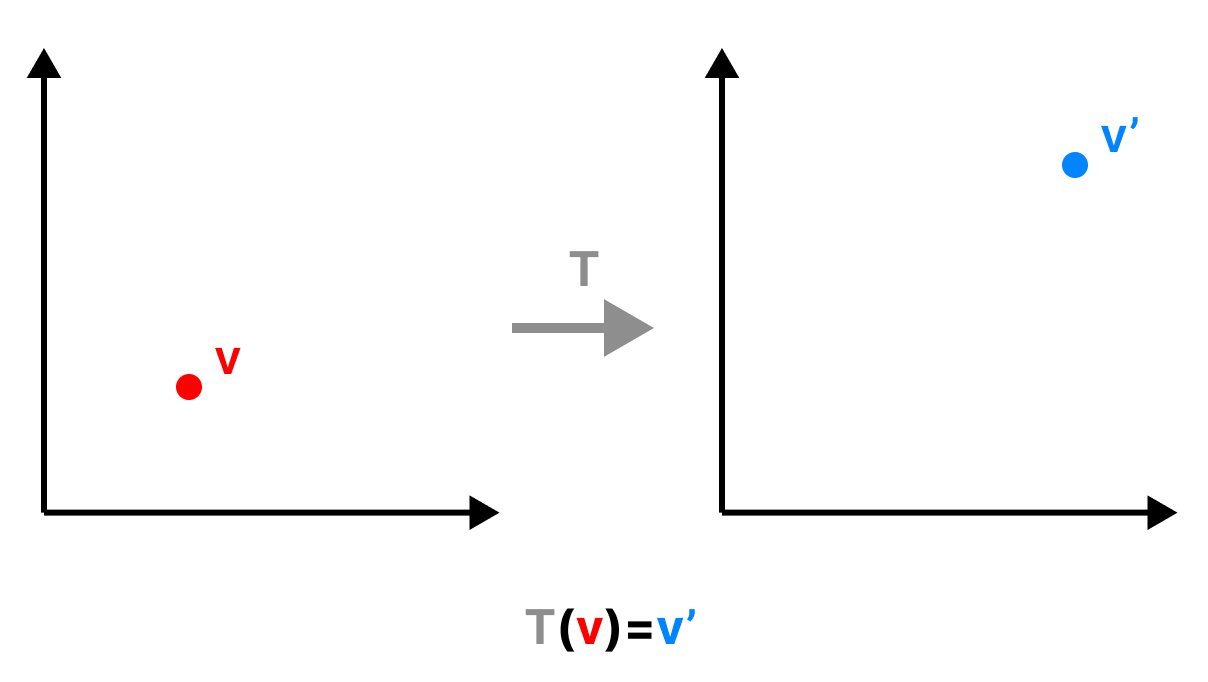
Given an input vector
Therefore, we can represent our transformation as follows in 2D:
Similarly in 3D:
If
Scaling
Of the types of transformations you've learned about in lecture, the simplest is scaling. Recall that, to scale
and scale each by the corresponding factor. Since
From this simple exercise, we can construct a transformation matrix to represent scaling, using the transformed basis vectors as its columns. Here it is in 2D:
And in 3D:
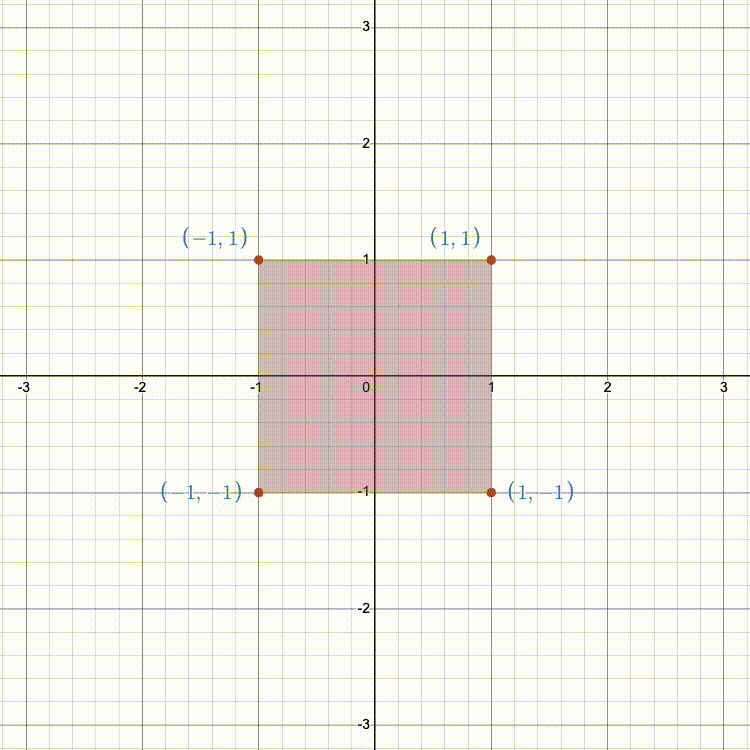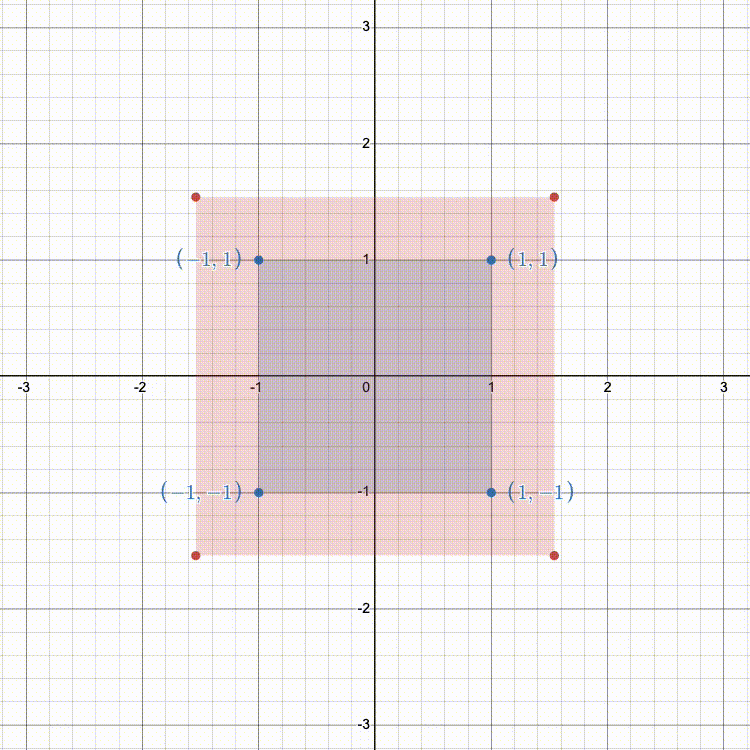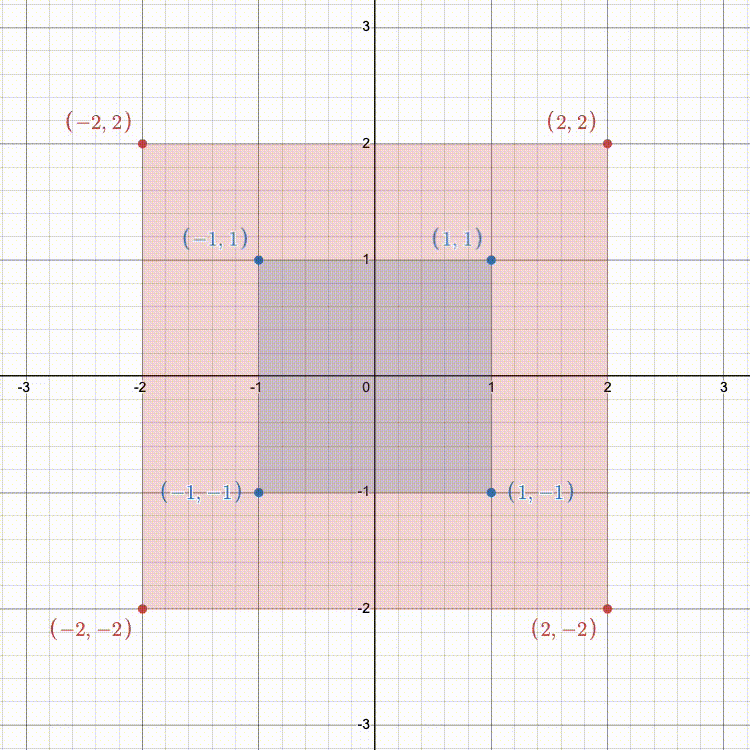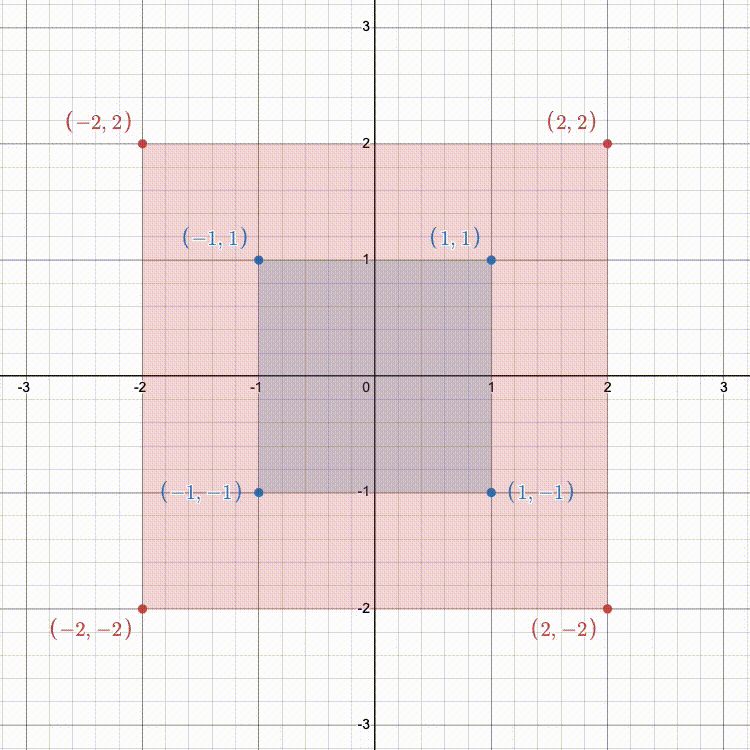
In transforms.cpp fill in getScalingMatrix so that it returns a 3x3 transformation matrix (as a glm::mat3). This matrix should represent a scaling along all 3 axes, based on the 3 input scale factors.
You may not use any built-in GLM functions for building transformation matrices (namely, scale, translation, or rotate) for this lab.
How to initialize a glm::mat3
There are many ways to intialize a matrix with values using glm, but here are the ones you'll most probably end up using:
- Single value:
glm::matN(float x)initializes anNxNmatrix withxalong the diagonal. - All values:
glm::matN(float x_11, ... float x_n1, float x_12 ... float x_nn)will initialize anNxNmatrix with thevalues passed in. Note that these values must be specified in column-major order. - Column vectors:
glm::matN(glm::vecN v_1, ... glm::vecN v_n)will initialize anNxNmatrix with theNvectors passed in as the columns.
Warning: glm uses column-major order. Please be aware of this, especially when specifying all values at initialization.
Rotation
Rotation in 2D follows a similar idea as scaling. We can rotate the standard basis vectors
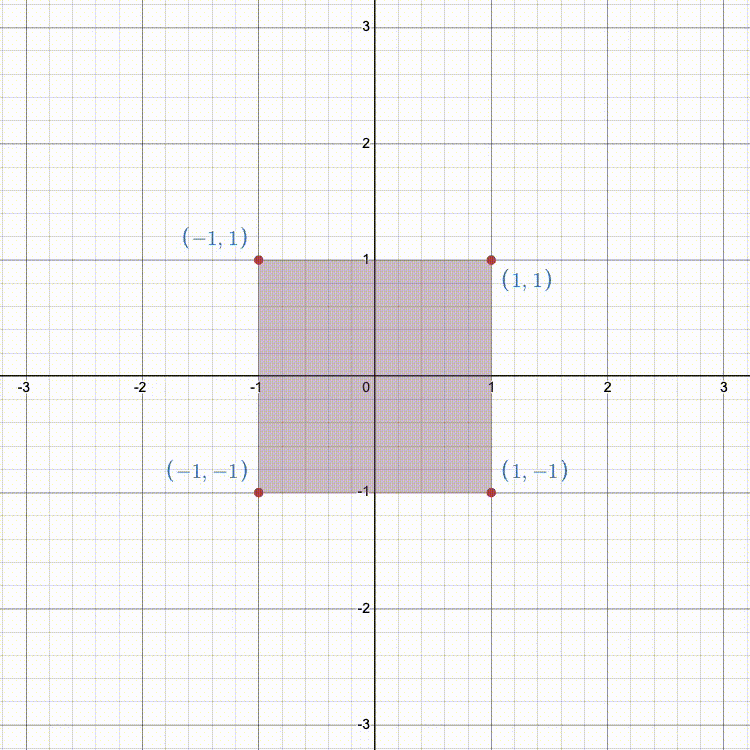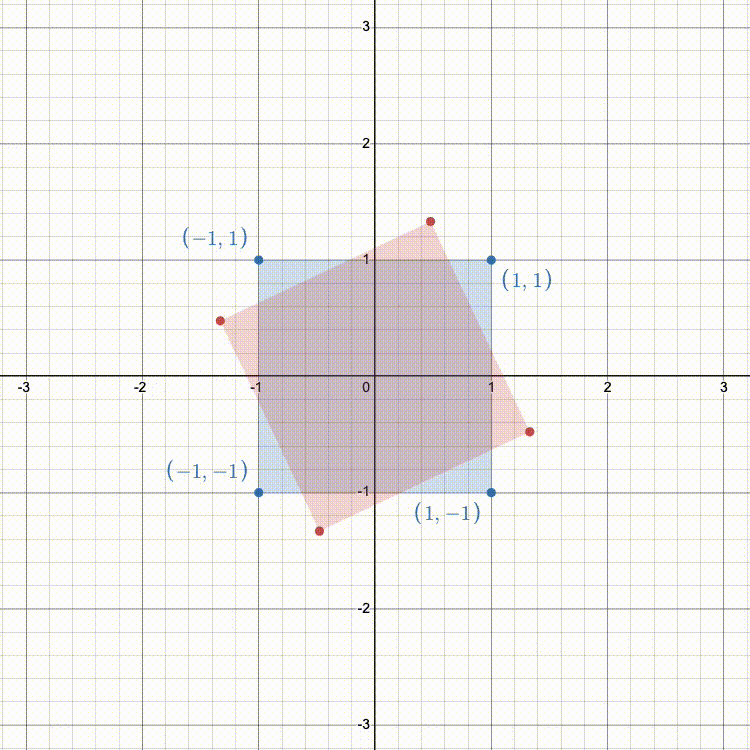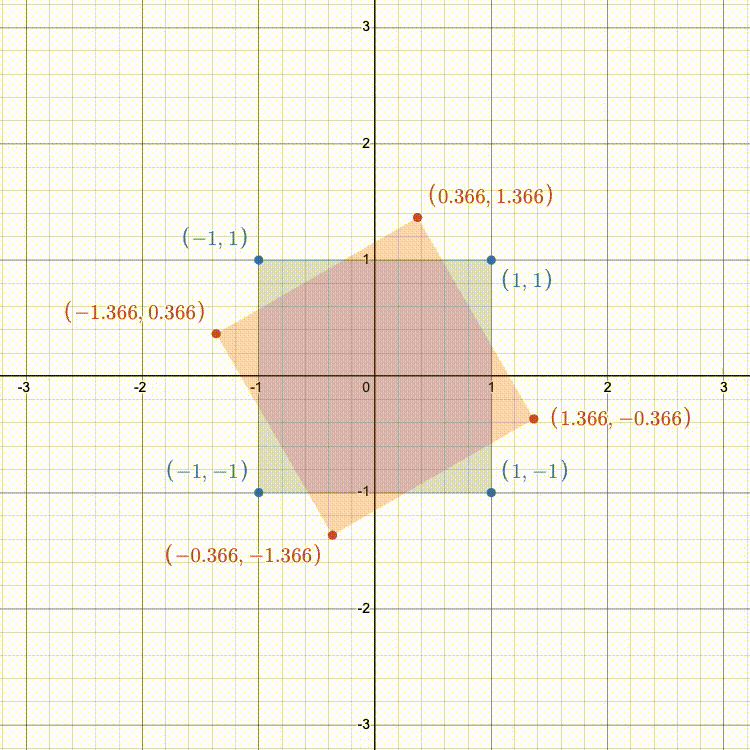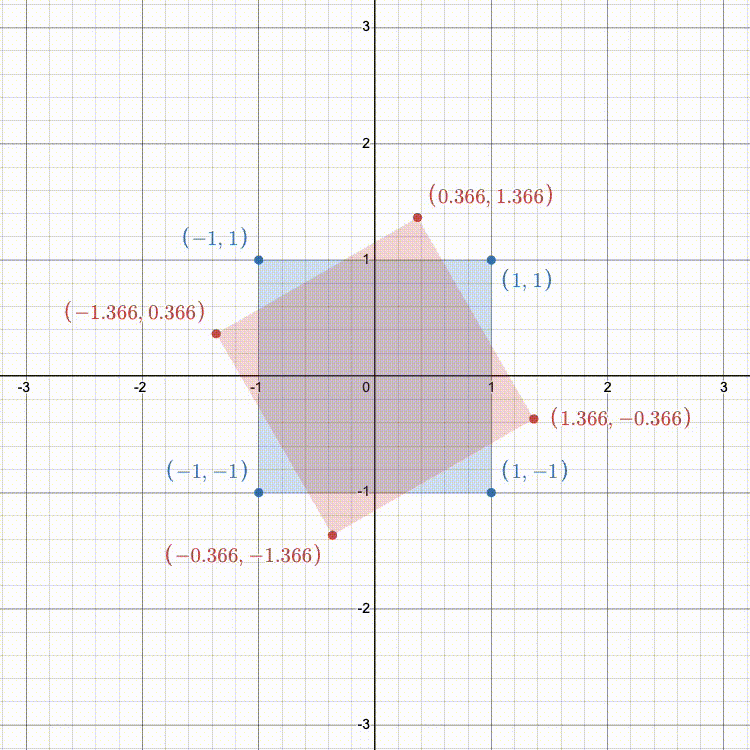
In 3D, this is a bit more complex. Rather than always rotating CCW about the origin, 3D allows for rotation around any arbitrary axis.
There are many ways to describe rotations in 3D (as covered during the lectures), but for now we'll use the axis-aligned Euler angles approach as this is the simplest for when we construct our own matrices. For this, we define 3 rotations, one about each standard axis, and then compose them in a specified order. We use
Fill in getRotationMatrixX, getRotationMatrixY, and getRotationMatrixZ so that each returns the 3x3 transformation matrix that rotates about the named axis by the given angle. These functions might be useful, and you can use glm::radians to convert angle units.
Remember that glm expects column-major order during initialization!
Note:
glmand the<cmath>library expect radians angle units.
3D rotation about arbitrary axes requires composing the above individual transformations. We'll discuss the composition of transformations a bit more later, but just keep in mind that there are different orders in which you can apply the rotations. One common approach is to multiply the
To transform
Such that:
Pay attention to the sequence of multiplication that
Translation
Translation is where our previous understanding of transformation matrices stops working. Until now, we have only been working with linear transformations, which always preserve the origin, i.e.
Translation, on the other hand, is an affine transformation, which does not necessarily preserve the origin. Generally speaking, linear transformations are a strict subset of affine transformations.
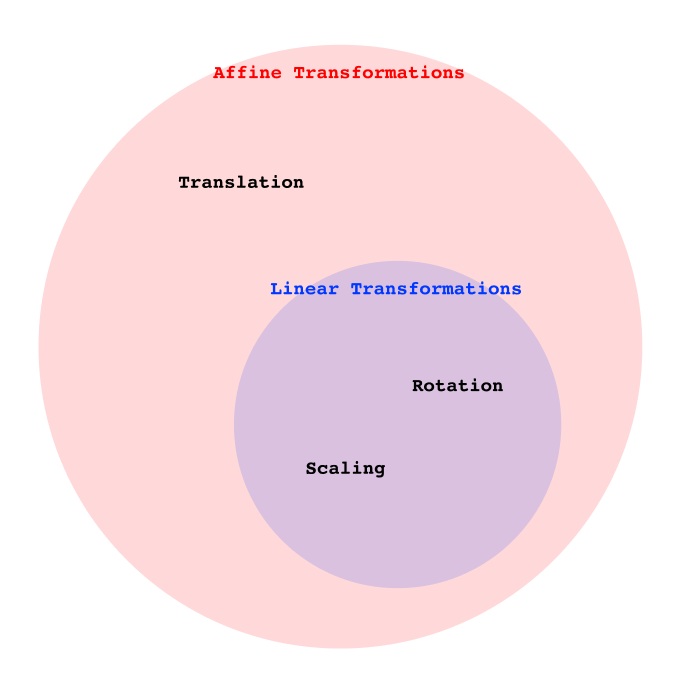
Extra: more information about transformation classification
There are many ways to classify transformations. In the paragraphs above, we are considering their mathematical formulation: translation is not a linear transformation as it does not preserve the origin, and this conclusion is entirely based on the definition of what a linear transformation is.
You will soon see that what is non-linear in one dimension, can actually be linear in a higher dimension 😉.
There is, of course, another way to look at classify transformations. We might do so based on what geometric features they preserve:
Type Of Transformation What They Preserve Examples Displacements Distances and oriented angles Translations Isometries Distances and angles Rotations, reflections, and the above Similarities Ratios between distances and angles Uniform scaling, and the above Affine transformations Parallelism Non-uniform scaling, shear, and the above Projective transformations Collinearity Perspective projection, and the above Adapted from the Wikipedia page on geometric transformations
In this lab, we will explore only affine transformations. However, by the time you're through with CS 1230, you will be well familiarized with projective transformations as well.
To illustrate the problem we are now facing, suppose we wanted to translate points by some non-zero vector
Oh dear. No matter what values we put in 2x2 matrix, the output can never be equal to non-zero vector 2x2 matrix is not sufficient for representing a translation of a 2x1 point in this way (and the same can be shown for 3x3 matrices, with 3x1 points).
If we wish to represent translations as matrices, we must now introduce homogeneous coordinates.
Homogeneous Coordinates
While homogeneous coordinates are pretty simple to use, they might be somewhat challenging to understand. The idea is this: take any existing point or vector, and just add another dimension to it. Then, do the same for transformation matrices.
In 3D, for example, this turns a 3x1 point into a 4x1 point. We typically refer to this new, fourth dimension as
For points (position vectors), we set
Reminder: points vs. vectors
A point is characterized by having a specific position in space.
A vector has a magnitude and a direction, but no location.
One way to think of this mathematically is that a vector is the difference between two points, like the displacement from one to the other. It doesn't matter where it starts and ends. Conversely, points only have a location, but no sense of size or orientation.
In 2D, points become
Likewise, in 3D, points become
As mentioned earlier, we must also enlarge our transformation matrices: in 2D, they become 3x3; and in 3D, they become 4x4.
Extra: how does this affect what we've learned so far?
Fortunately, adding the extra dimension does not break how points and vectors work. We won't prove this, but here are two examples:
But, we'll have to modify our previous linear transformations to be compatible with our new matrix size. For scaling and rotation, we simply add another dimension (i.e. another row and column) with
Note how the new, "extended" portion of the matrix resembles the identity matrix. Intuitively, this is because we do want our transformation matrix to still do the same thing, and not change its behaviour just because we added another dimension.
Now that we've got a 4x4 matrix to work with, we can use the added dimension to account for our translation values
See how adding the
Example: attempting to translate vectors
Since
Now that we know how to perform translation in n dimensions by using an (n+1)x(n+1) matrix, here's an example to tie it all together:
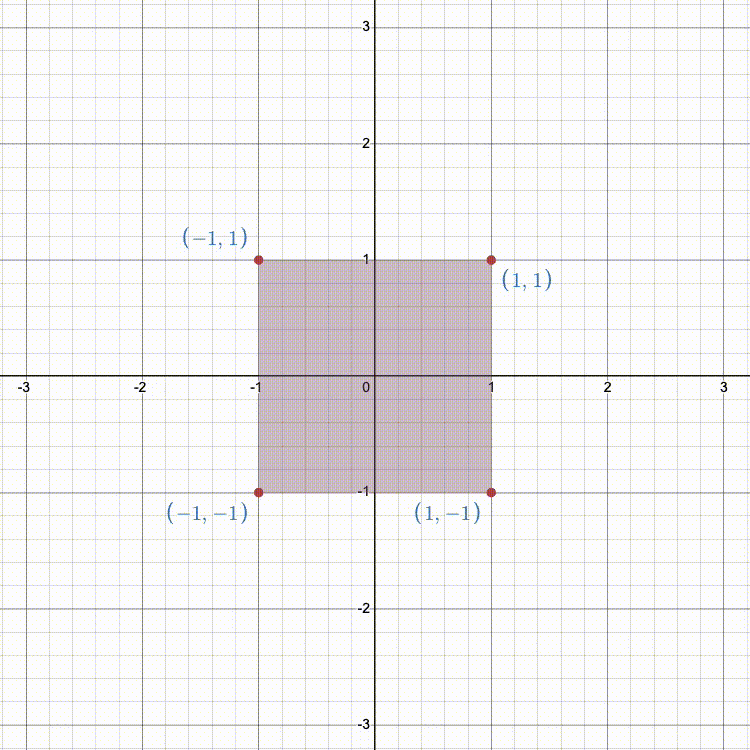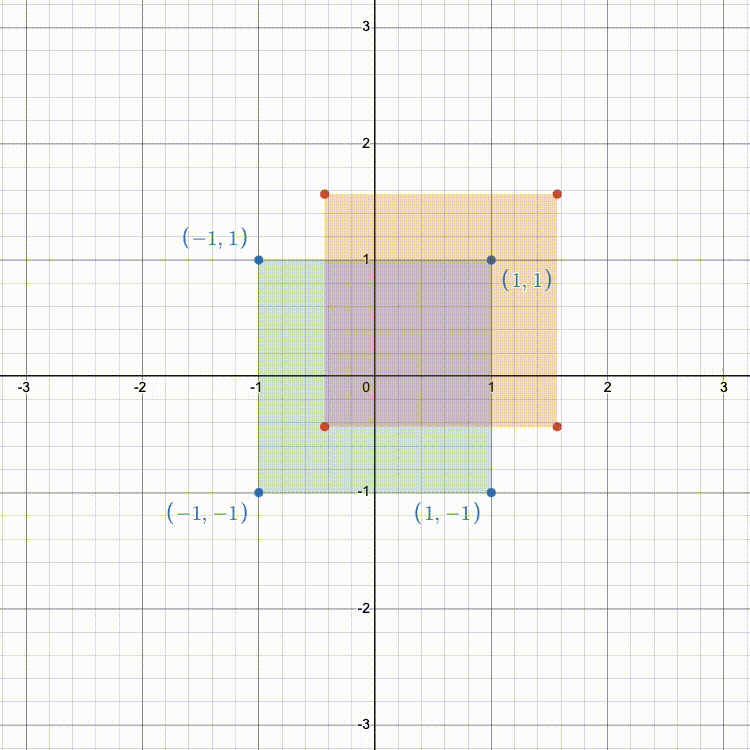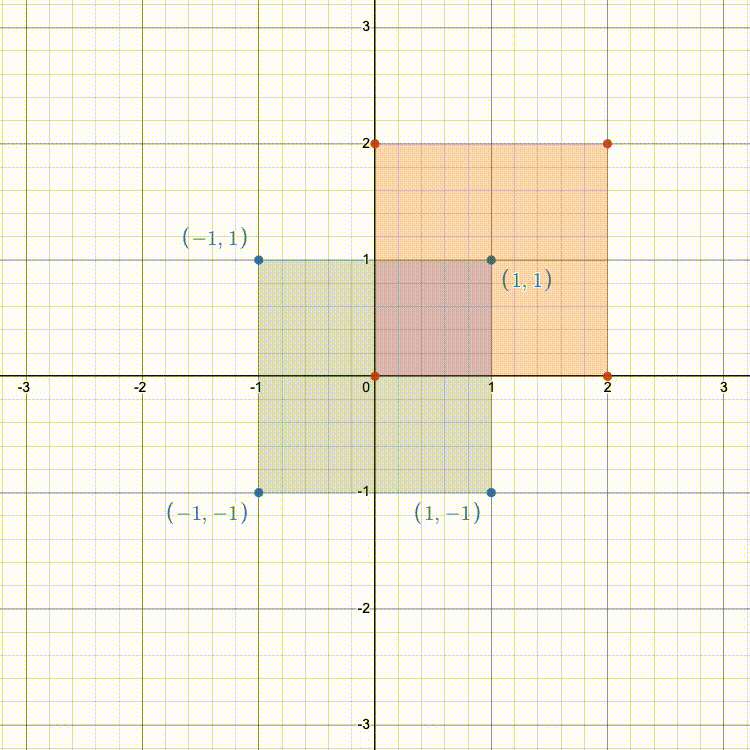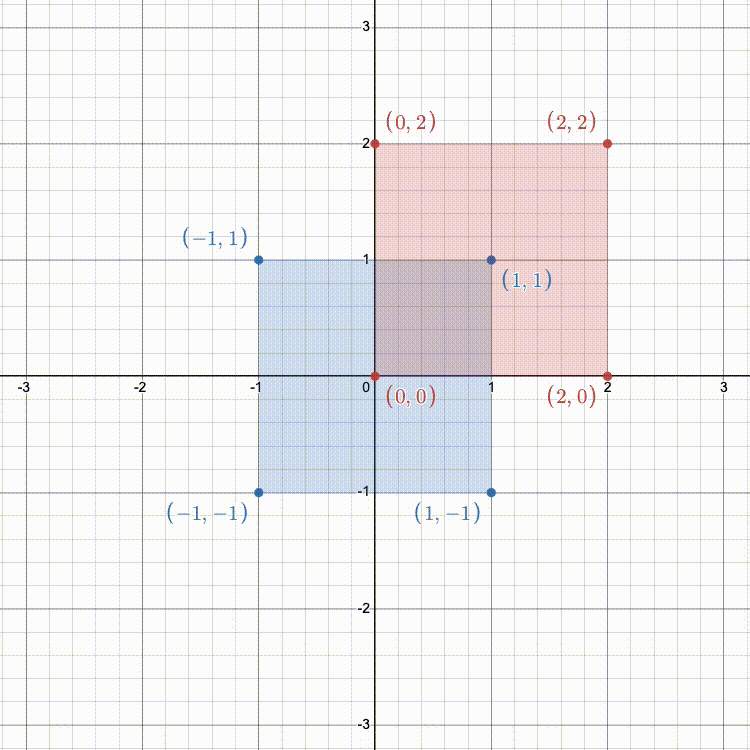
Fill in getTranslationMatrix() so that it returns the 4x4 transformation matrix (as a glm::mat4) that translates along each axis by the given coordinates.
Next, go back and modify your previous functions so that the matrices they return are compatible with our new homogeneous coordinates. Modify getScalingMatrix(), getRotationMatrixX(), getRotationMatrixY(), and getRotationMatrixZ() to return glm::mat4s. Don't forget to modify the headers in transforms.h!
Applying Multiple Transformations
As briefly mentioned when discussing rotation about multiple axes, sometimes we want to apply multiple transformations to the same point. We can do this by composing transformations. Mathematically this is represented by multiplying the respective matrices in the order that the transformations are applied.
If we have two transformations
Due to the associativity of matrix multiplication, we can multiply
Note that matrix multiplication is not commutative and therefore the order you apply transformations does change the outcome! The product
may not be the same as .
Ordering S, R, and T
If you have one object that you want to apply multiple individual scale, rotation, and translation transformations to, you should be careful of the order in which you compose the transformations. Usually, you want to use a standardized order in which you apply transformations to maintain consistency.
One common ordering is TRS. This means that scaling is first, then rotation, then translation.
How does this change the outcome?
Let's say we have a square at the origin that we want to perform the following transformations on:
- Scale x by 1.5 and y by 2.5
- Rotate by 45°
- Translate by (3, 3)
Here's what happens if we translate, then rotate, then scale (SRT):
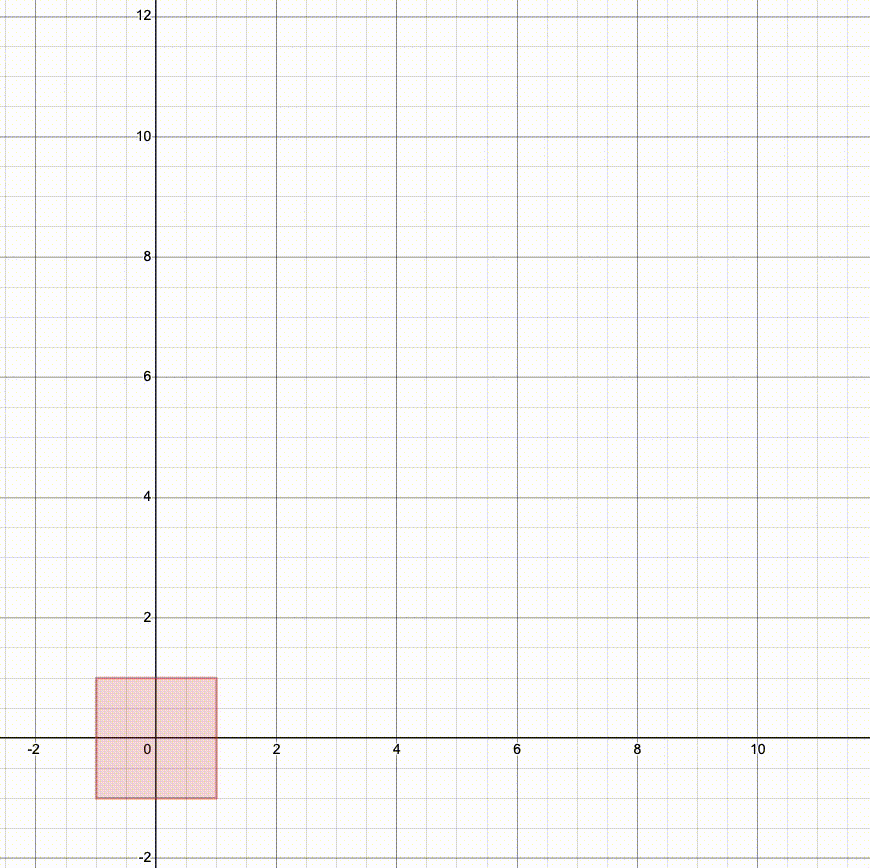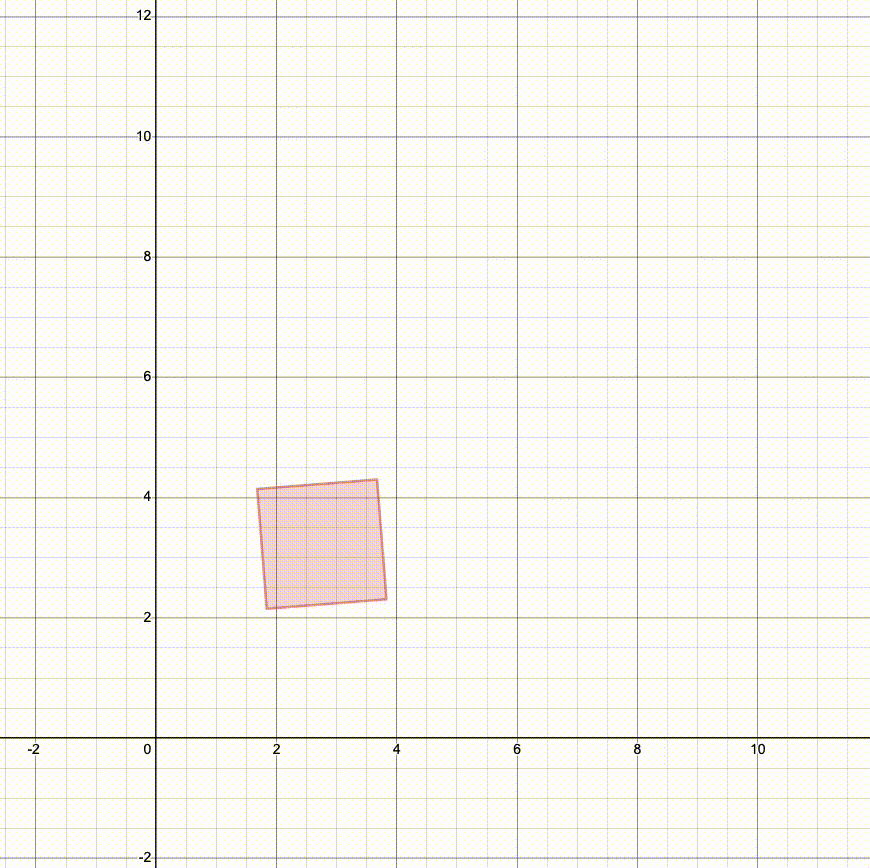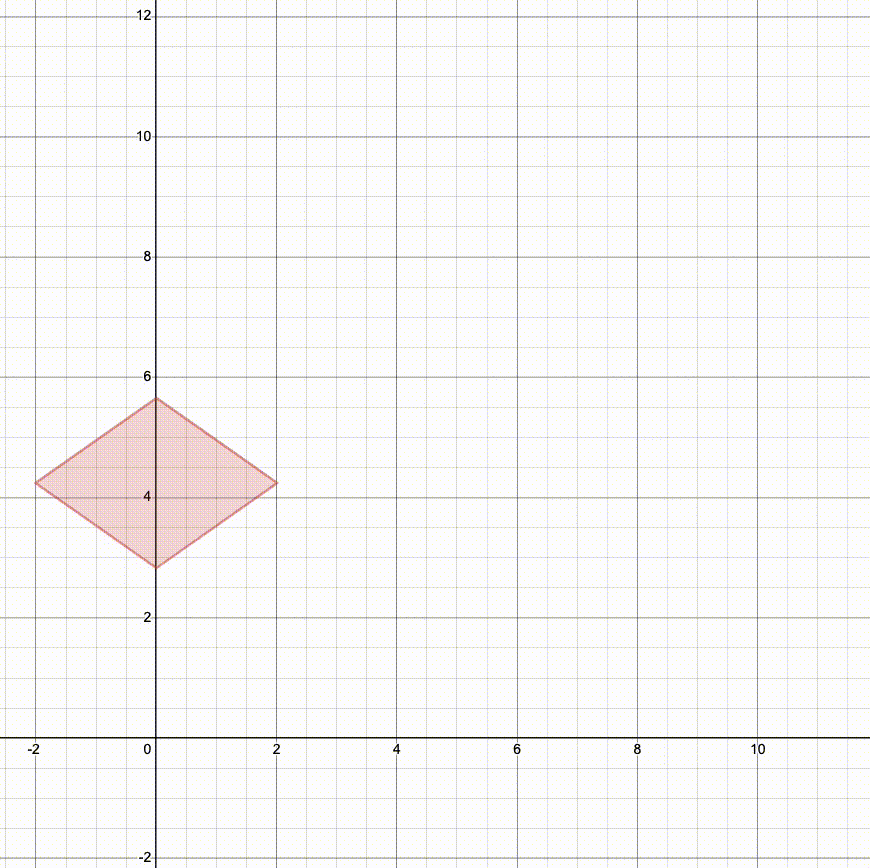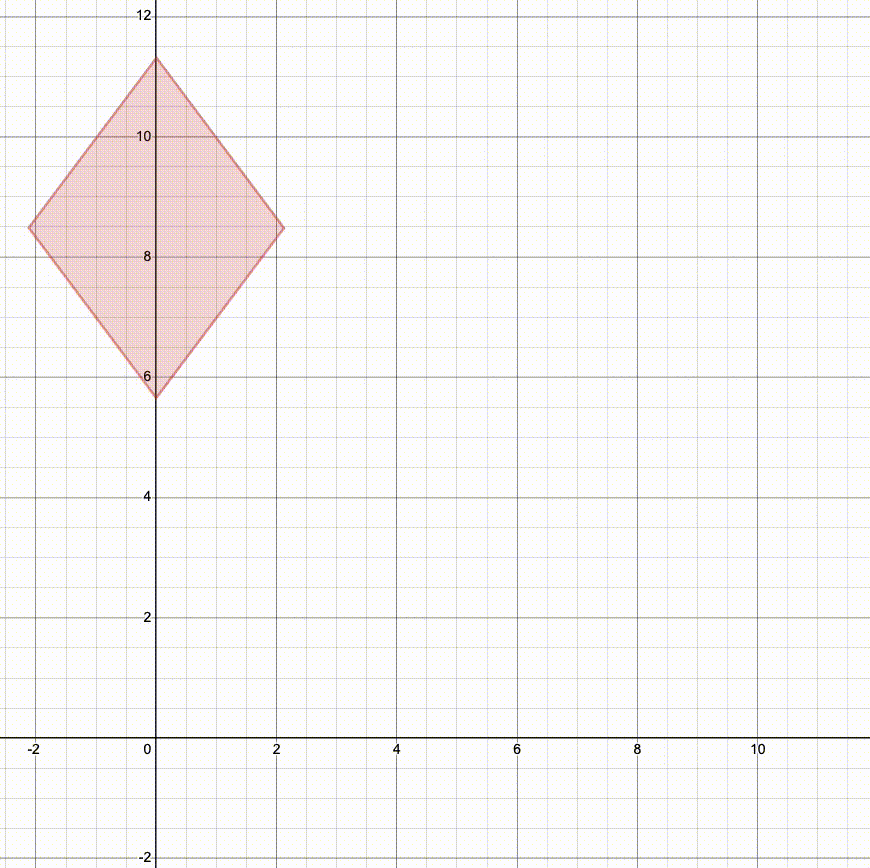
Notice how we scale along the standard axes, so rotating first changes the way the object is stretched. Both rotation and scaling are centered at the origin, so translating first changes the final position.
And here's what it looks like if we scale, then rotate, then translate (TRS):
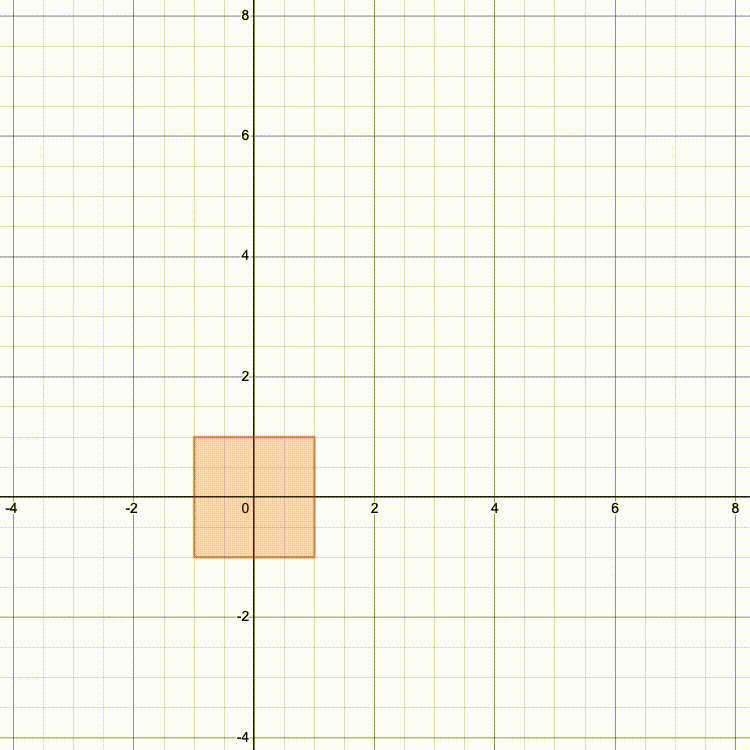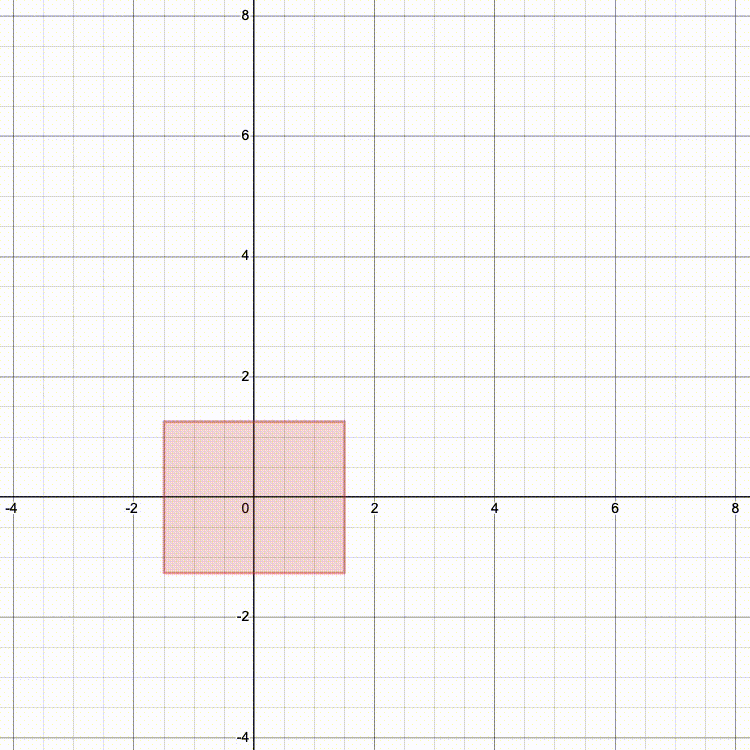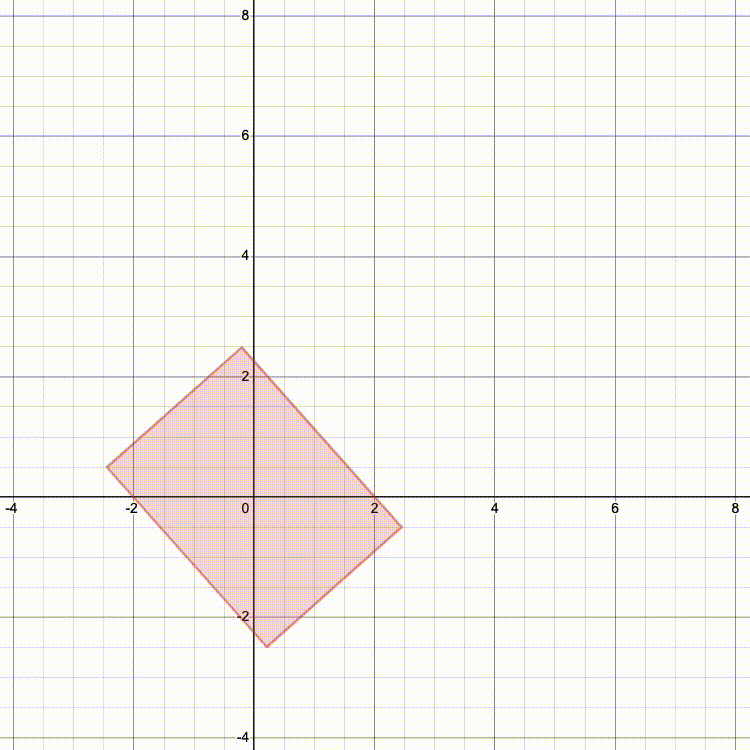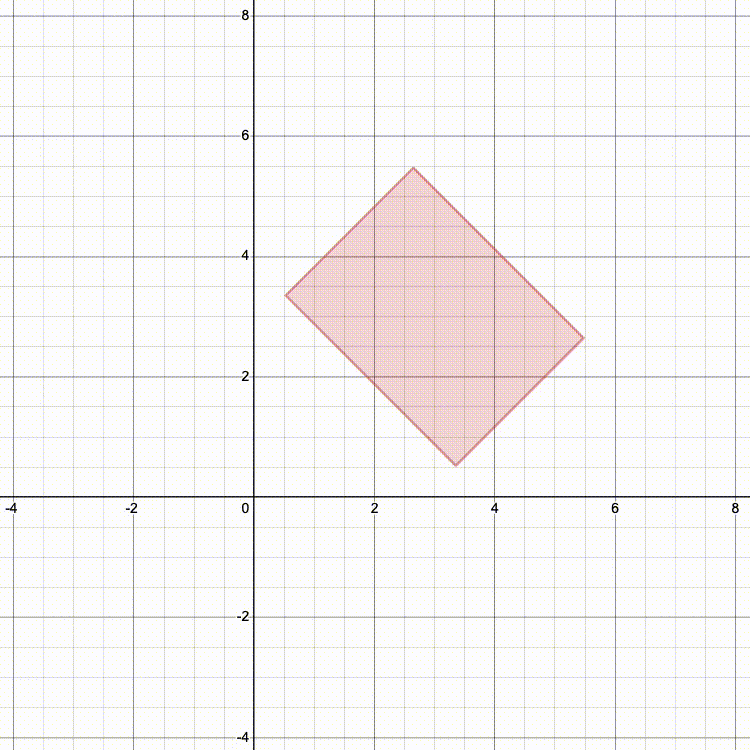
Which looks more like the result you'd expect?
Introducing The Transformation Graph
In lecture, you learned about scene graphs, which allow us to organize objects in a scene using a hierarchy of transformations. For the next part of the lab we'll be looking at this graph which contains the transformations we want to create for the lab demo.
There are a lot of different parts of this graph to understand, but for now let's focus on some of the labeled transformations. A, B, C, and D all denote individual transformation matrices that involve some combination of scaling, rotating, and translating.
How to read the transformations
At the top of the graph is the world origin. From it, the rest of the objects and camera branch off, with nodes in between to represent the transformations applied to the objects and camera.
Here's a guide to our notation of transformations:
S X,Y,Z: scale by factors X, Y, and Z along the corresponding axes
R X,Y,Z,𝜃: rotate by angle 𝜃 about the axis defined by unit vector [X,Y,Z] ([1, 0, 0] would denote the x-axis, for example)
T X,Y,Z: translate by X, Y, and Z along the corresponding axes
Fill in functions getMatrixA, getMatrixB, getMatrixC, and getMatrixD using the functions you defined in Tasks 1-4 to return the matrices corresponding to the transformations described in the graph.
Great! Now we have matrices corresponding to each edge of the graph. But what does it mean to have multiple of these branching off into different layers of the graph's hierarchy?
Nesting Transformations
Looking at our graph again, each leaf of the tree is an object in the scene. Traversing the tree from the object to the root will create a path through all of the transformations applied to that object in the scene. So to transform Object 1 to world space, for example, first apply transformation A then C. The cumulative transformation matrix of an object in the scene, resulting from this ordered multiplication of matrices, is referred to as the object's model matrix.
Previously, we emphasized the need to order each of the T, R, and S transformations. Now we may be dealing with multiple matrices composed of multiple T, R, and S transformations, but for the higher level ordering we follow the graph hierarchy.
Demo
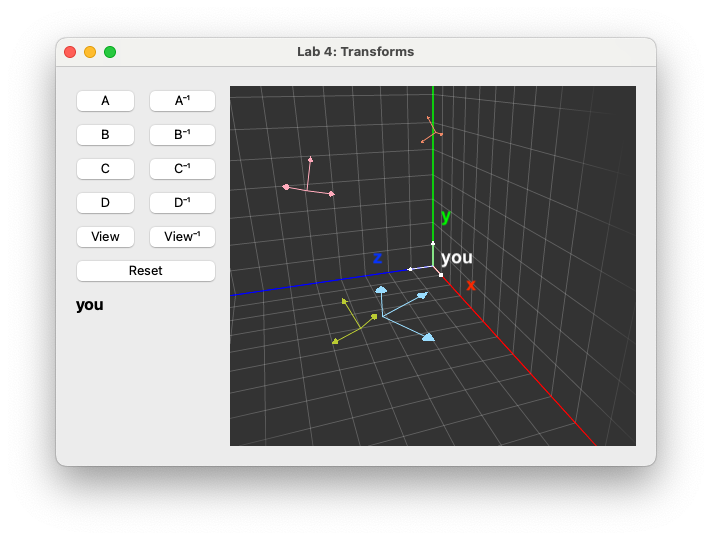
To help you understand the transformations in the above graph, we've created a visualizer in the lab stencil. When you run your code you should see something like this:
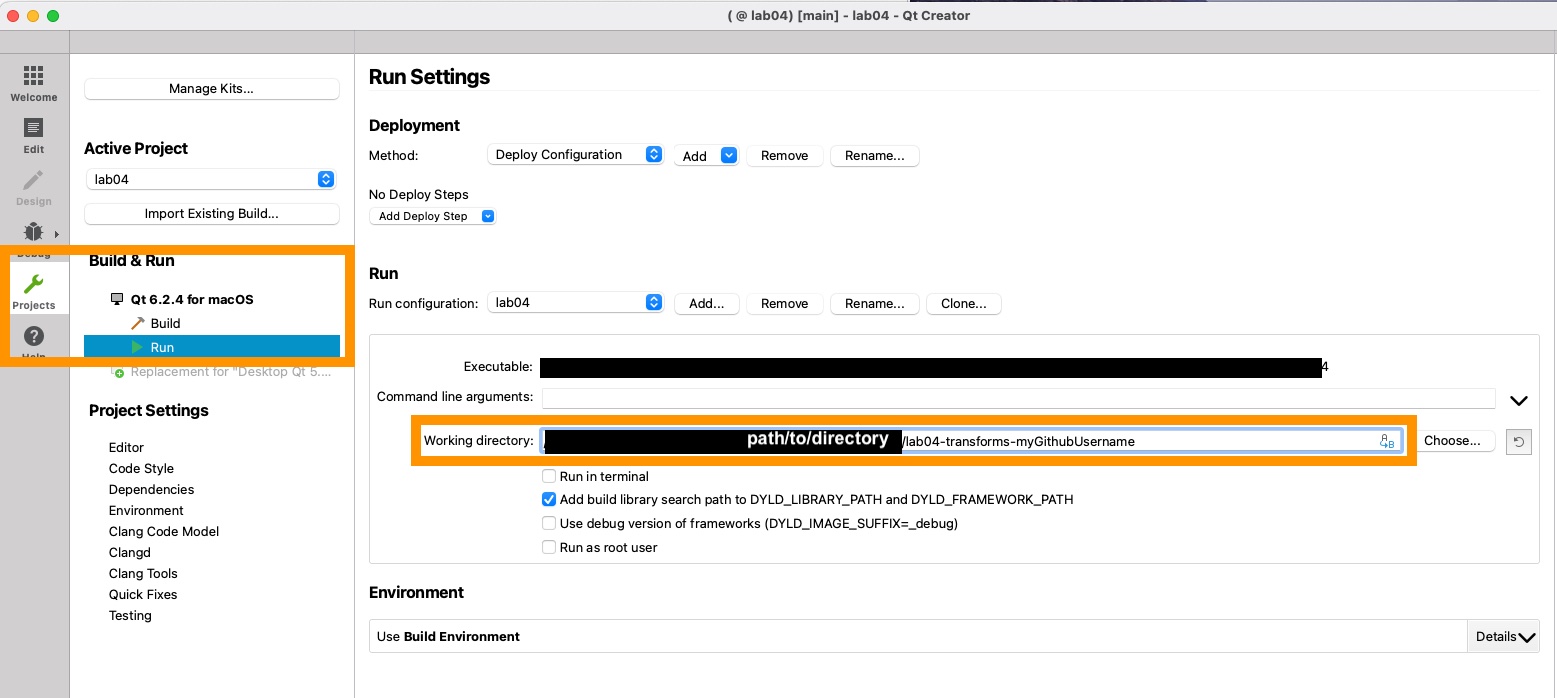
Having issues running your code?
If you run your code and don't see the axes, or if your program immediately crashes with an error along the lines of
terminating with uncaught exception of type std::runtime_error: Failed to open shader: resources/shaders/grid.vert
this is for you!
On the left side of Qt Creator go to the Projects > Run menu and check your working directory. Ensure that the listed filepath is the absolute path to the root folder of the lab git repo. The most likely issue is that the program is unable to load the shader files we use for rendering the scene because the filepaths are relative to the root directory!
Correct:
You can click and drag with the mouse to move around and scroll to zoom.
The white grid in the background represents the world coordinate system. The white axes at the origin represent your current coordinate system. Though they aren't labeled in the demo, these are labeled here for your reference.
There are other colored sets of axes throughout which represent the coordinate systems of the different objects in the scene as described in the graph. These are not labeled because in the next task it will be up to you to figure out which belongs to which object.
Each of the buttons A, B, C, and D are linked to the functions you completed in the last task to return transformation matrices. Pressing any of these buttons will apply the corresponding function's transformation to the white axes. We have also provided you with inverse buttons for each of these that will return the inverse of the corresponding matrix. (Don't worry about the "View" or "Rotation" buttons for now, you'll be implementing those later.)
As you press the buttons, the text underneath that says "you" will update to reflect the order of transformations you use. Pressing the "reset" button will move your axes back to the origin and reset this label.
Use the A, B, C, and D buttons to transform your coordinates from the world origin to each object's coordinates represented by the different colored axes.
You can think of the white axes as starting in each object's object space, and your goal is to follow the transformation graph to transform it into world space.
If you have implemented your matrices correctly and apply them in the correct order as described in the provided transformation graph, you should see the white axes line up with another colored axes. For Objects 1, 2, and 3, complete this process and make note of the orderings and/or the transformation string displayed by the demo as you will need to be prepared to demonstrate this at checkoff.
Note: Each colored axes is an object from the transformation graph. This means it may or may not require multiple transformations to reach it. Using the transformations you created, you should be able to match 3 of the 4 colored axes. We recommend rereading the paragraphs above this task if you are confused.
As a quick visual debugging exercise, we've provided you with a function called getInverseRotation which is supposed to return the inverse of any given rotation matrix.
The function relies on the useful fact that the inverse of a rotation matrix is its transpose.
However, there's a problem with the function which you'll need to find.
- In the visualizer, press the Rotation button. Its corresponding function is already implemented and rotates your coordinate space about the vertical axis by a small angle.
- Next, press the Rotation
button (which calls getInverseRotation). Does it apply the transformation you expect it to? - Identify and fix the bug(s) in
getInverseRotation().
- You may not use
glm::inverseorglm::transposefor this task. - Verify that you've fixed the bug by applying Rotation followed by Rotation
or vice versa; your coordinate system should return to its original state at the end.
You might notice that (other than your moving white axes) there are 4 axes objects in the demo, but you only matched 3 objects so far. The fourth one is actually the camera, the last leaf in our transformation graph. Until now, you've been working with transformation matrices that take objects and transform them to different placements in the world. Just like every other object in a scene, we can adjust the camera with a transformation matrix.
Camera View Matrix
The virtual camera's placement in world space can be defined by the same rotation and translation transformations we have been working with. These transformations help us to situate the camera relative to the world's coordinate system.
However, a key part of rendering is being able to figure out where points in the world are relative to the camera's view. To do this, we can use a transformation matrix that represents the opposite of the camera's transformation in the world. By applying this inverse transformation to points in the world, we can convert them to the camera's coordinate system; here, the camera is the origin from which it views everything else. We refer to this matrix that transforms objects in world space into camera space as the view matrix.
The camera is defined by its position
The camera is translated from the world origin to
The rotation of the camera is fixed by the look and up vectors, look being the direction the camera points and up being a vertical direction relative to the camera's view.
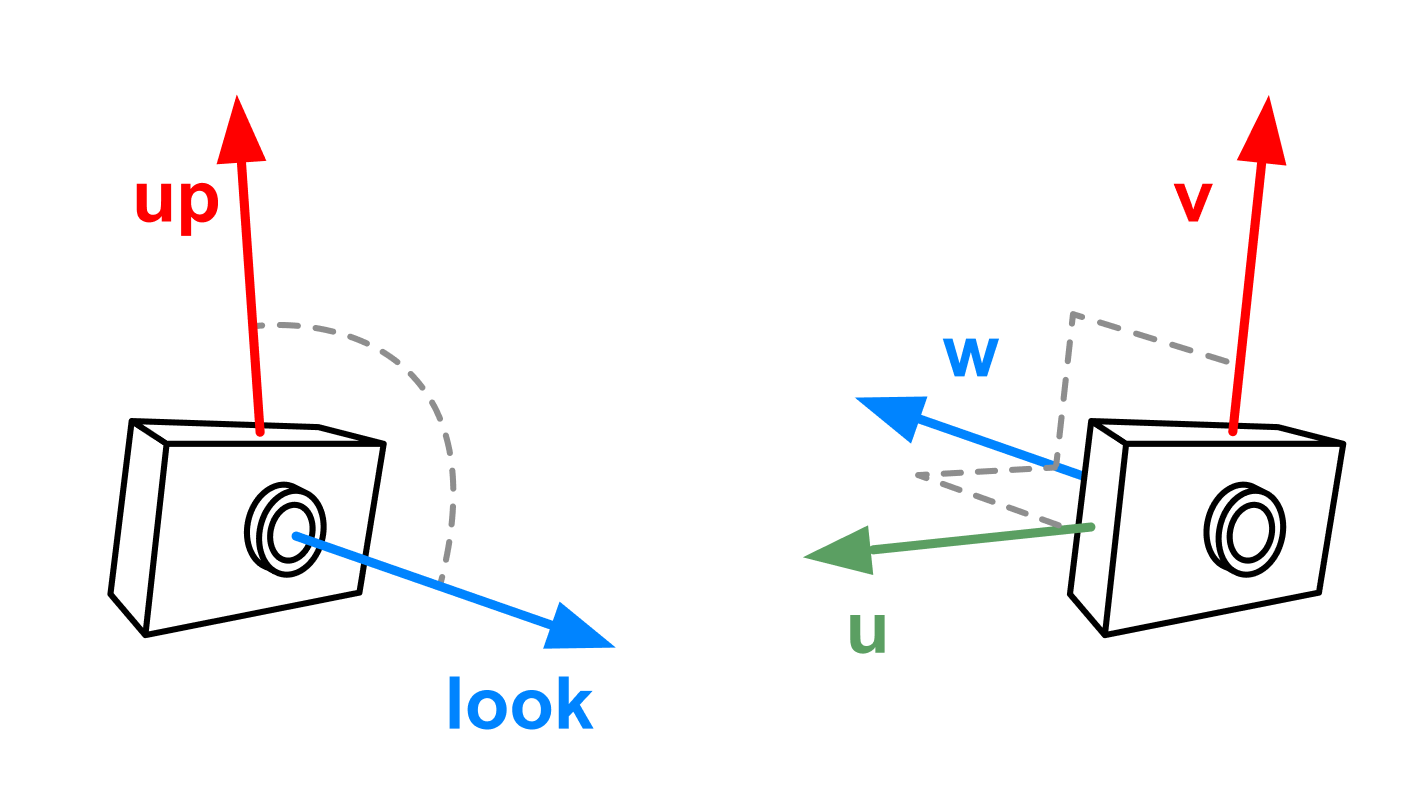
(Note that look and up are not always orthogonal but that calculating uvw accounts for this.)
Recall from the lecture that we can use these to calculate axes
For the rotation component of the view matrix, we are once again inverting the transformation that rotates the camera in world space. Unlike with the other objects, we haven't defined an angle of rotation about each axis, but we do know that the standard basis vectors along the
Finally, putting the rotation and translation together, we get one matrix for transforming other objects into the camera's coordinate system.
Wait, why T then R?
Wondering why our view matrix does translation first and then rotation, even though earlier we said rotation should usually come first?
As with the objects' model matrices that we looked at previously, the matrix that transforms the camera to world space is composed of a rotation first then a translation. Since the view matrix is the inverse (it transforms objects from world space to camera space), we must reverse the order of the multiplication.
Fill in getViewMatrix in transforms.cpp to return the view matrix of the camera using the function parameters for pos, look, and up. These functions might be helpful for working with vectors.
If you run the demo again now you should be able to use the "view" button to apply the view matrix transformation. Careful though! Remember that the view matrix transforms the world coordinates to the camera coordinates (note the direction of the arrow in the graph). If you want to view the transformation of the camera coordinates to the world coordinates (i.e. moving your white axes from the origin to the camera's axes in the demo), which button should you actually press?
Coordinate Spaces
In discussing transformations, we've mentioned the idea of transforming between coordinate spaces, but what are coordinate spaces? This is an important concept as you work on building your raytracer. You will often find that certain calculations make sense when you work with them in specific coordinate spaces, but when you're dealing with points and vectors in different spaces you need to know how to use transformations to move between them.
Here we'll cover the main coordinate spaces you will need to work with.
World Space
Think of world space as your default overarching coordinate system. Everything else gets placed into the scene relative to the origin and units of the world's coordinate system. World space is arbitrarily defined and acts as a fixed space within which everything else can be defined. In the transformation graph we've been looking at, it is the root that everything else stems from.
Camera Space
Camera space is what you learned about in part 4 of this lab. It is the coordinate system defined by the camera's position and rotation. In camera space, everything else in the world is relative to the camera's view, with the camera being placed at the origin, and its
Object Space
Object space is pretty much what it sounds like - the coordinate system in which an object is defined. In the demo, these are represented by the little sets of axes drawn for each object in the scene.
Why do we need coordinates specific to each object?
For example, you might want to make a bunch of variations of a sphere that are all different sizes and in different locations. Rather than define each sphere separately, we can define a single sphere as a set of points around an origin, and then transform those points. You can perform calculations on points in the sphere relative to its own central origin, and then use its model matrix to get those points in world space.
In task 2 of this lab you have already found model matrices for objects in the given graph. These take points from the object and transform them into positions in world space. Knowing this, can you think of a way to take a point from a transformed object in world space and find its position in the object's coordinate space?
Relating All Three
That was a lot of information! Here's a simpler graphic that helps to sum up the relationships between everything we covered in this lab:
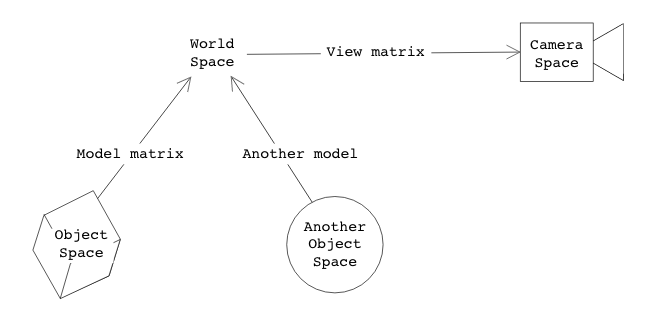
The arrows indicate the direction of transformation that the labeled matrix provides. An object's model matrix will convert from that object's space to world space. The view matrix will convert from world space to camera space. The inverses of these matrices provide the transformation of the opposite direction.
Consider the following situation where you have a scene with a camera, a cube, and a light as such:
You know the coordinates of point
Your response should be no more complex than just stating "multiply __ and __ to get __ in ______ space. Then..."
End
Congrats on finishing the Transforms lab! Now, it's time to submit your code and get checked off by a TA. You should be prepared to run the demo and show that you can move the axes according to tasks 6 and 7. Have your answer to the question in task 8 ready, as well.
Looking Ahead
In this lab, you implemented your own functions to build transformation matrices, and learned how to create cumulative transformation matrices, which you will continue to work on in the next lab, Lab 5: Parsing. Though you wrote the matrices yourself this time, you might find built-in functions such as glm::scale, glm::rotate, and glm::translate to be helpful and save you some time in the future. Always remember to look at the documentation, though, as you'll notice some differences like how glm::rotate uses the angle-axis representation of rotation instead.
Submission
Submit your GitHub link and commit ID to the "Lab 4: Transforms" assignment on Gradescope, then get checked off by a TA at hours.
Reference the GitHub + Gradescope Guide here.